The Problem
Causal knowledge is what your most experienced people carry — the accumulated understanding of why things go wrong, not just that they do. Why the loss ratio deteriorates in specific conditions. Why a customer profile that looks low-risk produces high churn. Why a control that worked in one jurisdiction fails in another.
That knowledge cannot be extracted from data. The data may be consistent with multiple causal structures, and deciding which one is correct requires someone who understands the mechanism. When that person retires or moves on, the reasoning goes with them. The organization is left with the outputs — the decisions they made — but not the structure that produced them.

How It Works
The library is built through three interlocking stages and grows continuously.
Domain experts draw the causal graphs and populate the probability tables. Every arrow is a causal claim they are willing to defend. The elicitation is a structured, formal model-building process.
Each Structural Causal Model (SCM) is stored in a shared library — versioned, auditable, owned by the organization. When an expert leaves, their model stays. When a new expert joins, they inherit a working model they can interrogate, challenge, and extend.
Users query the library in plain language. The answer is not generated — it is computed from the encoded causal structure. Each answer makes the next question easier to ask and easier to answer.
What Changes
A document retrieval system can tell you what was written about a problem. An SCM library can stand in for the domain expert who is not in the room — computing what they would conclude, given the evidence, in the time it takes to ask a question.
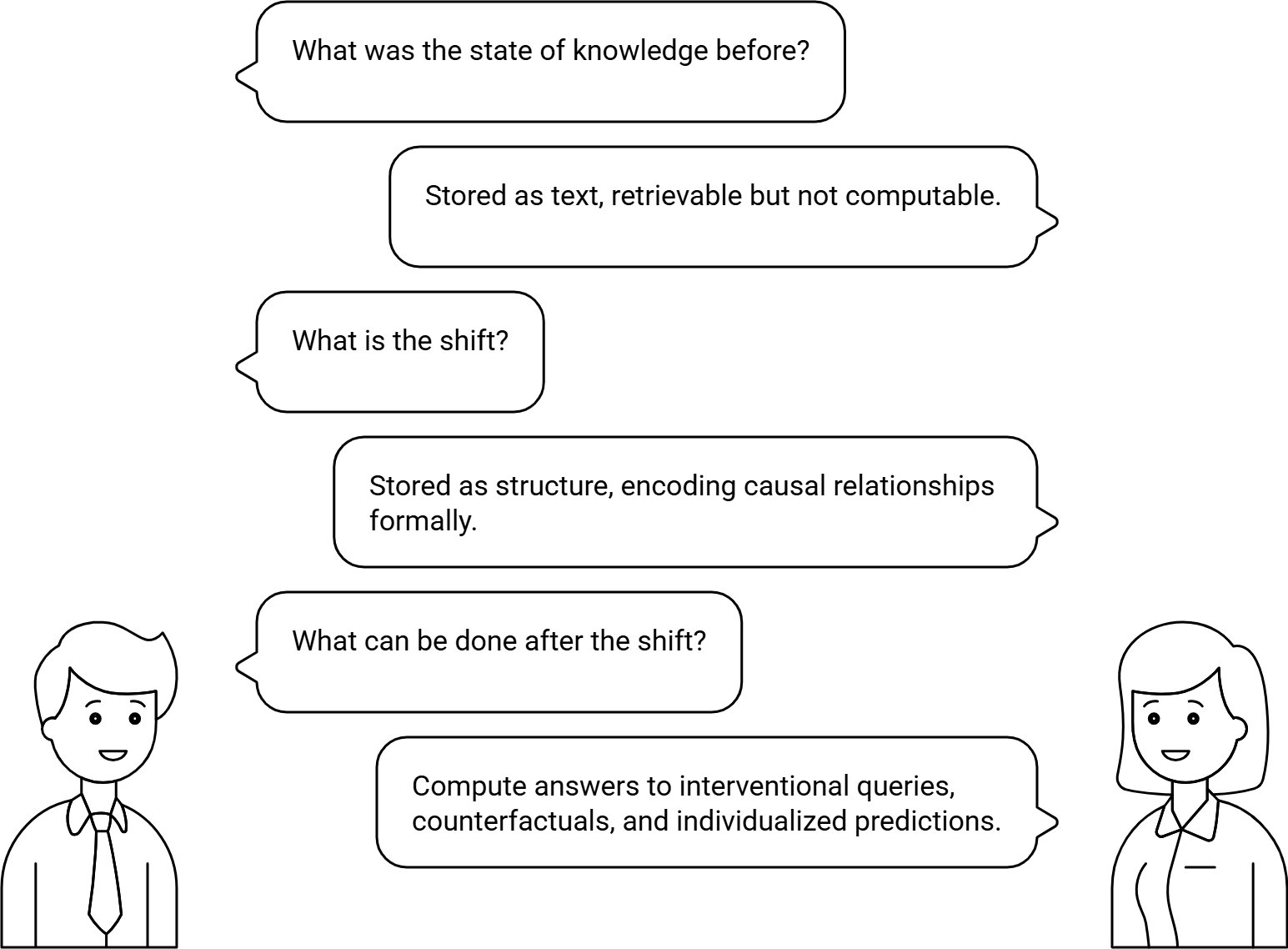
The library improves with use. When a model's predictions diverge from what actually happens, that divergence identifies precisely which part of the causal structure needs revision — which arrow was drawn in the wrong direction, which probability was miscalibrated. A trained neural model that underperforms tells you it needs retraining. An SCM that underperforms tells you which assumption was wrong and who is best placed to correct it.
The graph is its own explanation. When a regulator asks how a decision was made, the derivation already exists — which variables were considered, which relationships were applied, which probabilities were used. There is nothing to reconstruct after the fact because the model never operated as a black box.
Who Does What
Draws the causal graph, assigns the probabilities, validates the model against their experience. Their contribution is irreplaceable — causal structure cannot come from data. The software is a commodity. Their knowledge is not.
Asks a question in plain language. Receives a computed answer — not a prediction, not a summary. The user never touches the model. The complexity is absorbed by the architecture.
Building your organization's causal knowledge — eliciting it from your domain experts, encoding it into SCMs, and making it queryable — is a structured engagement with four phases.