The Moment
An analyst walks into a weekly meeting with three charts. Claim frequency is drifting in one region. Loss severity is trending in another. Premium leakage is ticking up in a third. The analyst has three explanations — one for each chart — and each is defensible on its own. The meeting proceeds on that basis for forty minutes.
Then the senior underwriter, the one who has been through two soft markets and one regulatory reset, says quietly: “These are the same thing. We haven’t named it yet. But it’s the same thing.”
Everyone who has built models for consequential decisions has seen this moment. The claim is not that the analyst is wrong. It is that the three surface patterns are downstream of a single unobserved driver, and that the three independent explanations on offer — however reasonable individually — will collectively mislead. The expert cannot, at this point, name the driver. They know it is there.
This is not experience in the vague sense. It is not pattern-matching. It is not a faster version of what a statistician would eventually conclude from more data. It is a specific kind of inference with a specific formal structure, and it has been named and characterized for a hundred and fifty years.
The Formal Name
Charles Sanders Peirce, in 1878, distinguished three modes of inference: deduction, induction, and abduction. Deduction derives consequences from known causes. Induction derives rules from observed cases. Abduction does something different: it proposes the hypothesis that, if true, would explain the observation. Peirce saw abduction as the only mode of inference that introduces new ideas — the only one that is genuinely creative.
Modern philosophy of science has sharpened the distinction further. Selective abduction picks the best explanation from a list of candidates already in the model. Creative abduction does something more radical: it posits a new theoretical concept — a new variable — that was not previously part of the representation. Gerhard Schurz formalized the distinction in 2008 and anchored the justification for creative abduction in Reichenbach’s Common Cause Principle: if two properties are correlated and neither causes the other, they are effects of a common cause.
Feldbacher-Escamilla and Gebharter (2018) then showed the payoff. Creative abduction — the move from correlated observations to the hypothesis of an unseen driver — is structurally identical to inference over a Bayesian network with a latent common-cause node. The underwriter’s move is the move the Bayesian network makes when an analyst draws in a new parent node to explain why three child nodes are correlated in a way their individual CPTs cannot account for.
The diagram is three boxes below one box — rendered in a working Bayesian network below:
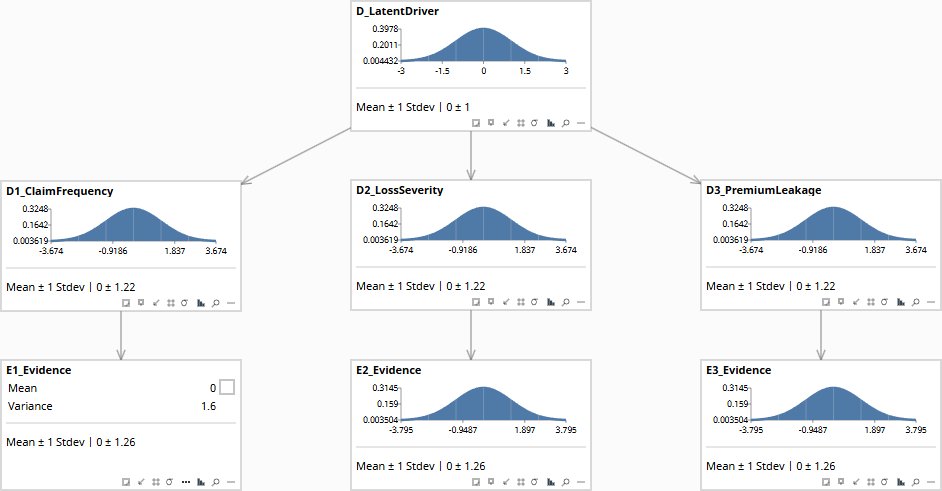
D is the driver the underwriter cannot yet name. D₁, D₂, D₃ are the three dispositions — the region-specific patterns. E₁, E₂, E₃ are what the analyst measured. The creative-abduction move is the introduction of D. Everything below D is what data already shows. D is the new node.
Three Necessary Conditions
The formalization is not metaphorical. Feldbacher-Escamilla and Gebharter identify three probabilistic conditions that make the abductive inference successful. They are worth stating plainly, because they map directly to what a good elicitation session is asking the expert to commit to.
D is not extreme. The proposed driver is not vacuously certain or vacuously impossible — 0 < P(D) < 1. The expert is proposing a real hypothesis, not a tautology.
Each disposition depends positively on D. P(Di | D) > P(Di). When the driver is present, each surface pattern becomes more likely than it would be without the driver. The expert has to commit to the direction of the causal arrow — D raises the probability of each of D₁, D₂, and D₃, not lowers it.
Each evidence node depends positively on its disposition. P(Ei | Di) > P(Ei). The measurements are genuinely informative about the dispositions — not decorative, not redundant.
These three conditions are what the expert is implicitly asserting when they say the three patterns are the same thing. The claim is not aesthetic. It is a set of inequalities over a joint probability distribution, and it is what makes the inference formally defensible. A good elicitation process writes these inequalities down.
The consequence of these conditions is visible the moment evidence is entered. Observe E₁ and the posterior on D shifts — and because D is a parent of D₂ and D₃, their posteriors shift too, even though nothing was observed about them directly:

Why Data Alone Does Not Do It
The natural next question is why a good structure-learning algorithm cannot make the same inference from the same data. The algorithm has access to the correlations. Why does it need the expert to posit D?
The answer is in the structure of the problem. The correlations among D₁, D₂, D₃ — or rather, among the observable E₁, E₂, E₃ — are consistent with more than one causal structure. They are consistent with a shared common cause. They are also consistent with chains, with selection on a collider, with feedback. The joint distribution does not, on its own, pick out the common-cause explanation.
This is Pearl’s observation, made precise: the same joint distribution is compatible with multiple causal graphs, and no amount of observational data resolves between them. What data cannot tell you is where the next arrow should go. Structure-learning algorithms that attempt to recover latent common causes from correlated observables are doing difficult work in a space that is not fully identified. They produce candidate graphs. They cannot, in general, select among them.
The expert resolves the ambiguity by bringing mechanism knowledge the data does not contain. They know, for reasons that do not appear in any dataset, that regional claim frequency and premium leakage share a common upstream driver — maybe a book-level reinsurance shift, maybe a broker-behavior change, maybe an emerging fraud pattern. The knowledge is about why the variables would be connected, not just that they are. That is the gap creative abduction fills, and that is why elicitation reaches answers structure-learning does not.
Clark Glymour, in a 2018 paper on creative abduction and factor analysis, puts this directly: the search problem for latent variables is formally hard, and the productive path is combining statistical procedures with substantive domain knowledge. The expert is not a slower algorithm. The expert is an input the algorithm structurally needs.
What This Means for Elicitation
This site argues for a specific engagement method: elicitation before data fitting. Get the experts’ causal structure onto the graph first, then fit parameters against data second. The argument has, until now, rested on practitioner experience and on the general claim that causal structure cannot be recovered from observation alone.
The formal account of creative abduction makes the argument sharper. Elicitation is not a concession to small samples or to stakeholder politics. It is the step of the inference that fundamentally data cannot do alone — the step where a new latent variable is posited on grounds the data cannot supply. Running elicitation first is not a preference. It is the structurally correct sequence, because the creative-abductive move must precede the parameter-fitting move.
The consequences are practical. When a senior expert says, in a session, “there is something else driving all three of these,” the right response is not to collect more data. It is to add the node, assign its parents and children according to the mechanism the expert is describing, and let the data fitting — which data is good at — happen next. The expert’s insight goes into the graph first, in the place where the inference formally requires an input data does not provide.
This also tells you when elicitation is dispensable: when the causal graph is already complete enough that the inference does not need new latent variables. In that case, the question reduces to parameter estimation, and standard methods apply. The creative-abductive move only matters at the structural frontier — the moment when the graph does not yet contain the variable the answer depends on. That moment happens every time a new domain is being encoded. It is the moment the expert is most needed, and the moment the method is most defensible.

The next time a thirty-year expert says “we haven’t named it yet, but it’s the same thing”, there is a formal description of what they are doing, a formal condition for what they are asserting, and a formal reason to put their node on the graph before the fitting starts.
If the method your team uses for encoding causal structure does not start with elicitation — the creative-abductive move that data cannot make — the graph is already missing the variables that matter most.
info@rung3.ai
The working model shown above: CreativeAbductionCommonCause.bayes — open in Bayes Server to enter evidence and watch the posteriors propagate through D.
Peirce, C.S., 1878, “Deduction, Induction, and Hypothesis,” Popular Science Monthly 13 · Reichenbach, H., 1956, The Direction of Time, University of California Press · Schurz, G., 2008, “Patterns of Abduction,” Synthese 164(2): 201–234 · Feldbacher-Escamilla, C.J. & Gebharter, A., 2018, “Modeling Creative Abduction Bayesian Style,” European Journal for Philosophy of Science · Glymour, C., 2018, “Creative Abduction, Factor Analysis, and the Causes of Liberal Democracy,” Kriterion — Journal of Philosophy · Pearl, J., 2000, Causality: Models, Reasoning, and Inference, Cambridge University Press.