An LLM produces fluent answers in the shape of causal reasoning. For Rung 1 questions — "what is in the data?" — the fluency is supported by a real capability: pattern recognition over text. For Rung 2 and Rung 3 questions — "what should we do?" and "what would have happened?" — the same fluency is unsupported. The shape is right; the calculation is missing.
The problem is structural and twofold. An LLM has no mechanism for causal reasoning — it learns the conditional distribution of tokens given context, which is a Rung 1 object by construction. And an LLM’s content is the aggregate of public writing — your specific organization, your experts, your operating environment, are not in it. The combination matters: an LLM, used alone, gives you generic reasoning in someone else’s voice, presented in the shape of a specific answer. The fix is not a better LLM. The fix is the right architecture — LLM as interface, with a causal model of your domain as the engine behind it.

Why it sounds like causal reasoning
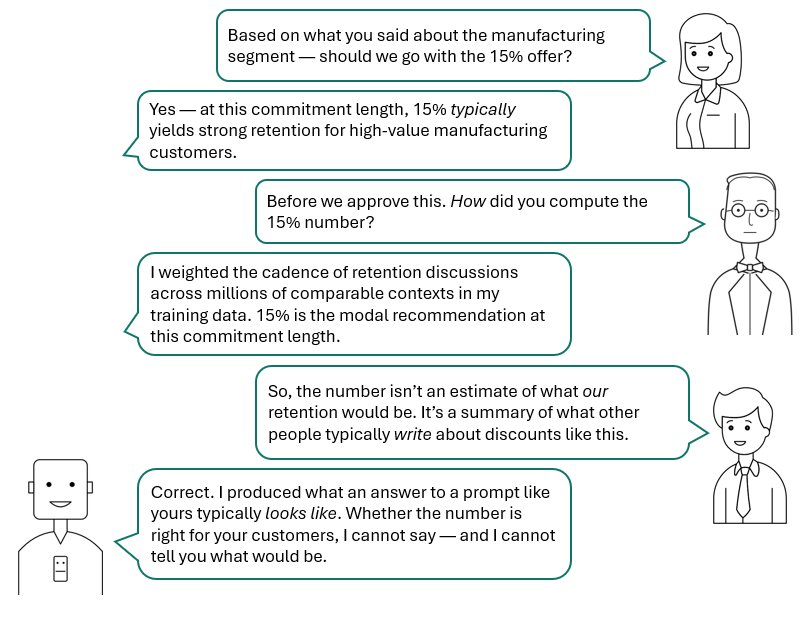
An LLM’s output reads like an answer to a causal question because the training data is full of causal answers. The model has absorbed the cadence, the vocabulary, the shape of causal reasoning — without absorbing the underlying mechanism. Asked whether A causes B, it produces what an answer to that question typically looks like in the corpus it was trained on.

The robot’s final line names the gap. Reading about cause and effect produces text in the form of causal claims; it doesn’t produce a model that can adjudicate new ones. The next sections explain the structural reasons that gap doesn’t close with scale.
Why the LLM answer fails
The failures cluster around four patterns. Each is structural — not a sign that the model is too small, the prompt is wrong, or the user is unsophisticated.
Failure 1 — The number that has no formal meaning
Ask an LLM "if we implement this control, by how much does risk decrease?" and you get an answer: "approximately 35–40%." The number is plausible. It is also unmoored from any computation. The LLM has not modeled the causal chain from control to risk; it has produced a token sequence shaped like a quantified causal claim. The cost is not the model being wrong — it's the model being precise without being checkable. A stakeholder cannot tell, from the output, whether the 35–40% is the result of structural reasoning or the result of similar numbers appearing in training-data passages about similar controls.
Failure 2 — The confident answer about your specific situation
Ask an LLM about a decision in your organization — your patient mix, your customer segments, your equipment, your competitive environment — and you receive a fluent response that assembles general patterns about similar-sounding entities. None of your specific causal structure was in the training data. The answer is responsive to the words in your prompt, not to the underlying reality those words refer to. The model has no way to flag the gap, and the user has no way to detect it.
Failure 3 — The intervention recommendation that is actually a prediction
The most common silent failure: a stakeholder asks a Rung 2 question ("what should we do?"); the LLM answers it as a Rung 1 question ("what tends to happen in cases like this?"). The user receives a recommendation; the model has computed a pattern frequency. The two answers are different objects, but the text is indistinguishable. The model's confidence is the same regardless of which question it actually answered.
Failure 4 — The counterfactual that wasn't computed
Rung 3 questions — "would this specific patient have done better under the alternative?" — require a structural model, not a language model. An LLM can write a paragraph that reads like a counterfactual answer, but the computation a counterfactual requires (abduction, action, prediction) is not the computation an LLM performs. The output has the form of a counterfactual without the content of one. Used as input to a real decision — a clinical-governance review, a regulatory submission, an audit committee — it has no defense.
Each failure has the same root: the question being asked is causal, and the tool being used is not. What follows is why — in two parts, because the structural failure has two faces.
It's unable to reason
A language model learns the conditional distribution P(token | context) — the probability of the next token given the preceding text, which is the object a language model is trained to predict. This is, by construction, a Rung 1 object (associational). It captures associational structure in text: which words tend to follow which other words, in which contexts, with what probability. Causal reasoning — P(Y | do(X)), the probability of outcome Y under an intervention that sets variable X, the apparatus of Pearl's Rung 2 and Rung 3 — is not derivable from P(token | context) no matter how much text the model is trained on. The mathematical gap is not bridged by scale. See the Ladder of Causation for the three-rung apparatus and Identification — do-calculus for the formal treatment. Norman Fenton makes the same argument as a public lecture: When machine learning from data is doomed to fail.
This is not a defect of current models that will be fixed by the next generation. It is a property of what the architecture computes. A larger language model is a larger Rung 1 system. It predicts text more accurately. It does not, by getting larger, acquire a causal graph, a do-operator, or a mechanism connecting its internal representations to the causal structure of the world.
Why it sounds like causal reasoning
The training data contains descriptions of causal reasoning — epidemiological papers, economics textbooks, blog posts about cause and effect, court decisions about liability, business cases describing strategic interventions. The LLM learns the surface texture of those descriptions. It outputs text that resembles causal reasoning the way a photograph of a kitchen resembles cooking. The resemblance is exact in every respect except the one that matters: a photograph cannot feed you, and an LLM's causal-shaped output cannot be acted on.
Concrete contrast
Ask both systems — an LLM and a Structural Causal Model (SCM) — the same question:
"Our marketing budget will increase 30% next quarter. What will happen to sales?"
The LLM produces a paragraph: "A 30% budget increase typically yields a sales lift of 8–15%, depending on channel mix and saturation effects. You should consider diminishing returns above a certain spend threshold, especially in mature markets..." The paragraph reads as a quantified causal claim. It is the conditional distribution of text that follows the words "marketing budget will increase 30%" in the training corpus — nothing about your specific channel mix, your customer base, your competitive context, or the actual causal mechanism in your operations.
An SCM produces a different object: "Under the structural model in marketing.dag, with the elasticity parameters elicited from the marketing leadership in the September workshop, the expected sales lift is X±Y, conditional on the assumptions named on lines 1–12 of the model specification. Sensitivity to the elasticity prior on the search channel is high; the result holds under perturbations up to ±20%." The number is computed from a model. The assumptions are inspectable. The sensitivity is bounded. A skeptic can challenge specific edges in the graph.
Both outputs sound authoritative. Only one has a defense.
It uses other people's content
Set aside the technical limitation for a moment. Even if an LLM could reason causally, the content it would reason from is the aggregate of public writing it was trained on: your competitors' published material, generic textbooks, journalism aimed at general audiences, regulatory documents, papers about other organizations' problems. None of which is about you.
Your specific causal knowledge is not in the training data, and cannot be put there. The categories it covers:
- Expert beliefs in your organization. What your senior actuary knows about your loss curves. What your chief clinician knows about your patient mix. What your process engineers know about your equipment's failure modes. These are causal structural claims, refined over years of pattern observation in your environment, never written down in any form a language model could ingest.
- Institutional priors. Your underwriting philosophy. Your clinical guidelines and the reasons they differ from the published ones. Your operational tolerances. These shape the causal structure of every decision in your organization and appear in no public corpus.
- Operating-environment specifics. Your supplier relationships, your local labor markets, your regulatory situation, your customer mix. The published descriptions of these are generic; the structural reality is yours.
- Prior post-mortems. What broke last time, why, and what the team learned. The lessons that shape every future decision in the organization. Almost never written outside internal documents.
When you ask an LLM about a decision in your domain, you get a borrowed answer assembled from strangers who have never seen your situation. The fluency masks the borrowed-ness. The model speaks with the same confidence whether it has access to relevant content or not — because, mechanically, it has access to some content, and the lack of access to your content is not a state the model can detect or report.
The contrast with structural-causal modeling
The first phase of a Rung 3 engagement is an audit that explicitly includes your experts' causal knowledge as a data source. The DAG that the engagement produces encodes your beliefs about your mechanisms in your environment. Two consequences:
- The reasoning is yours. The graph belongs to your organization. It can be inspected, defended, and revised by people who understand the domain.
- The IP is yours. A competitor with the same LLM access cannot replicate your reasoning, because the reasoning is not in any LLM — it is in your graph.
An LLM's knowledge cannot be made yours, because it isn't structured in a way that admits the substitution. You can prompt it with documents about your organization; the model can quote those documents back. But the structural causal model that should govern your decisions doesn't live in any document — it lives in your experts' heads. Eliciting that structure is what a Rung 3 engagement does. An LLM cannot do it because it has no graph to put the structure into.
Where the two failures compound
The technical and organizational failures interact badly. An LLM that returned generic reasoning in obviously generic language would at least be honest about its limitations — the user would see the gap. An LLM that returns generic reasoning in fluent, specific-sounding language hides the gap. The interface lies in both directions:
- It makes Rung 1 prediction look like Rung 2 intervention. The user asks "what should we do?" and receives a recommendation. The recommendation is, mechanically, a prediction about what tends to follow similar prompts in training data. The stakeholder cannot tell.
- It makes generic reasoning look specific. The user asks about their situation and receives a fluent answer that uses their terms. The terms are repeated from the prompt; the reasoning is from elsewhere. The stakeholder cannot tell.
This is why using an LLM as a strategic advisor is more dangerous than using one as a calculator. A calculator's limitations are visible — you can see what arithmetic it can and cannot do. A confident-sounding advisor's limitations are invisible. The same answer is delivered with the same fluency whether the model has computed a careful causal estimate (it cannot) or hallucinated a plausible-sounding paragraph (it can).
The composite failure has a name in adjacent fields: scientism. An answer that looks like the product of rigorous analysis without being one. Stakeholders trained to defer to apparent rigour cannot easily push back. Adjudication committees, regulators, and governance boards are particularly vulnerable, because their default response to a confidently-stated quantified claim is to engage with the claim rather than question whether a claim was actually computed.
The right architecture — LLM as interface, SCM as engine
The critique above is not an argument against LLMs. It is an argument against using an LLM where a structural causal model is what the question requires. The constructive position: LLMs are the right tool for the interface; SCMs are the right tool for the engine. For the full case for SCMs as the engine, see Why Structured Causal Models? — the constructive companion to this page. The two compose into a system that does what neither does alone.
The architecture in one picture: stakeholder asks → LLM parses → SCM (graph built by your experts) computes → LLM narrates → stakeholder reads.
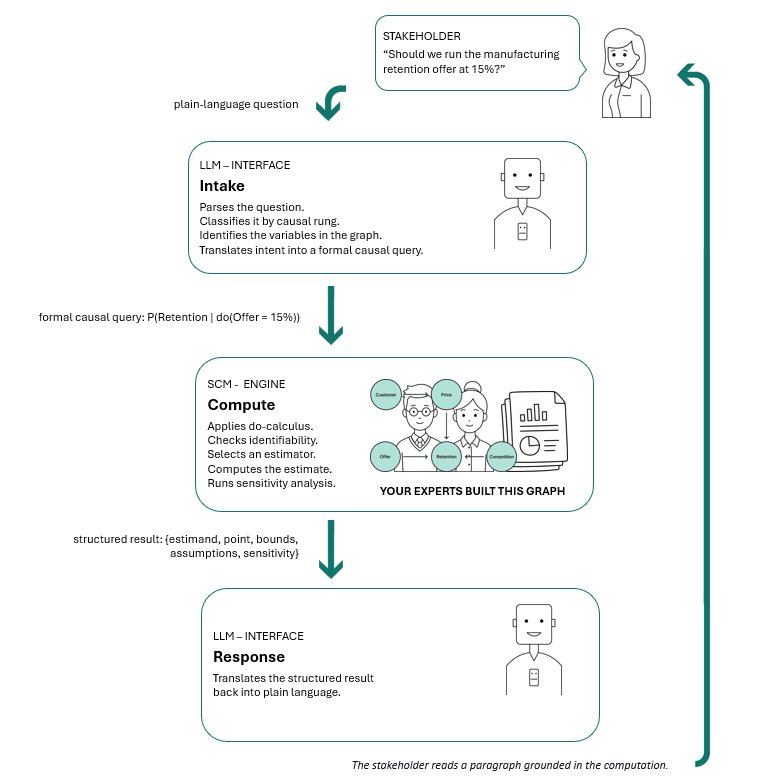
The neurosymbolic architecture:
- Question intake. A stakeholder asks a question in plain language. The LLM parses it: categorises by rung (Rung 1, 2, or 3), identifies the variables in the graph it refers to, and translates the intent into a formal causal query.
- Computation. The SCM runs the query. It applies the do-calculus, checks identifiability, selects an estimator, computes the estimate, runs sensitivity analysis. The output is a structured object: estimand, point estimate, bounds, assumptions, sensitivity profile.
- Response. The LLM translates the structured output back into plain language. The stakeholder reads a paragraph; the paragraph is grounded in a computation.
Three properties this gives you that an LLM alone cannot:
- The reasoning is auditable — because the SCM is the thing reasoning, and the SCM is explicit, inspectable, and challengeable. A reviewer can challenge a specific edge in the graph or a specific parameter prior. They cannot do this with an LLM output.
- The knowledge is yours — because the graph encodes your experts' beliefs about your mechanisms. The IP lives in the graph, not in the LLM. An LLM can be swapped for a different one without changing what the system reasons about.
- The interface is fluent — because the LLM is doing what it is genuinely good at: translating between plain language and formal queries. That is a Rung 1 task; it is the LLM's natural domain.
For the architecture in detail, see the companion pages on causal memory, SCM library design, expert knowledge encoding, and the translation problem at the interface.
The honest summary
LLMs are useful and getting more useful. They are the right tool for many tasks — summarisation, translation, code completion, document drafting, pattern recognition over unstructured text. They are the wrong tool for "what should I do in my specific circumstances, and why", for two compounding structural reasons:
- No mechanism. A language model cannot compute causal quantities, because
P(Y | do(X))is not derivable fromP(token | context). The limit is structural, not a matter of scale. - No access to your domain. Your specific causal knowledge — your experts' beliefs, your institutional priors, your operating-environment specifics — is not in any training corpus. The answers an LLM gives about your decisions are borrowed from strangers.
The right architecture uses an LLM as the interface to a structural causal model, not as a replacement for one. The SCM does the reasoning, encodes your knowledge, produces an auditable artefact. The LLM translates between plain language and the formal query. Both tools do what they are good at; neither is asked to do what it cannot.
This page argues against using an LLM alone for causal questions. Two adjacent arguments make the constructive case:
Why Structured Causal Models? — SCMs encode what your experts know rather than substituting for them. Three tools (ML, LLMs, SCMs), three jobs, in a single read.
LLM-Mediated SCM Libraries — the research frontier where the right architecture is heading. Five-layer system, citation-anchored, with an honest split between what is shippable today and what is research, not delivery.
If your team is currently using an LLM to answer Rung 2 or Rung 3 questions, the discovery procedure surfaces which of those answers are computed and which are borrowed. A half-day workshop completes the audit for one decision area.
info@rung3.ai