Language models bring linguistic intelligence and the world’s averages. Structural causal models bring the cause-and-effect logic of your specific organization. Together — LLM as interface, causal model as engine — they form an architecture your team can build, query, and own.
The literature calls this combination — language model plus symbolic reasoning — neurosymbolic AI. Causal AI is the version that operates on Pearl’s higher rungs, where the decisions worth making actually live.
For Executives → — if you lead technical analytics, strategy, or risk in a regulated industry. Three short tracks: which question your tools answer, which question your decision requires, and what the gap costs when they don’t match.
Pick the doorway shaped like your role. Each one ends at the same conversation.
How an engagement begins → — the default order in modeling work is questions, then data, then a model. The Rung 3 order is data first, questions second, model third. The inversion is the position — and the reason the procedure produces models that survive contact with reality.
Audit first, ask second. If you want to know what a project with me actually looks like in the opening weeks, start here.
About Risk → — if you came here looking for a specific kind of risk. Twenty-seven case studies organized into financial, operational, regulatory, clinical, and climate risk. Each card names what the standard analysis missed.
A topic-shaped cut through the same engagement portfolio. Start here if your entry point is the kind of risk you manage rather than the kind of role you have.
Cases → — twenty-eight worked engagements across eight domains. Each case names the question someone was about to answer with the wrong tool, and the question their decision actually required. Model files ship with every case.
Browse by domain. The numbers on each page were generated by the model in the file.
Why Structured Causal Models? — the full affirmative case in one page. The three-tool comparison (ML / LLMs / SCMs) and the constructive architecture, written for the analyst, CDO, or quant who is doing the technical evaluation.
One page, the central claim, at technical register.
Recent Work → — engagements at Merrill Lynch, PG&E, NVIDIA, Toyota, and fintech and health-tech ventures. Causal risk models for cybersecurity (FAIR-aligned), early-warning systems for utility infrastructure, financial systems redesign for cross-border private banking, product-reliability attribution at scale.
Typical engagement: eight to sixteen weeks across one decision domain. Read the work-shape from real engagements before you commit to one.
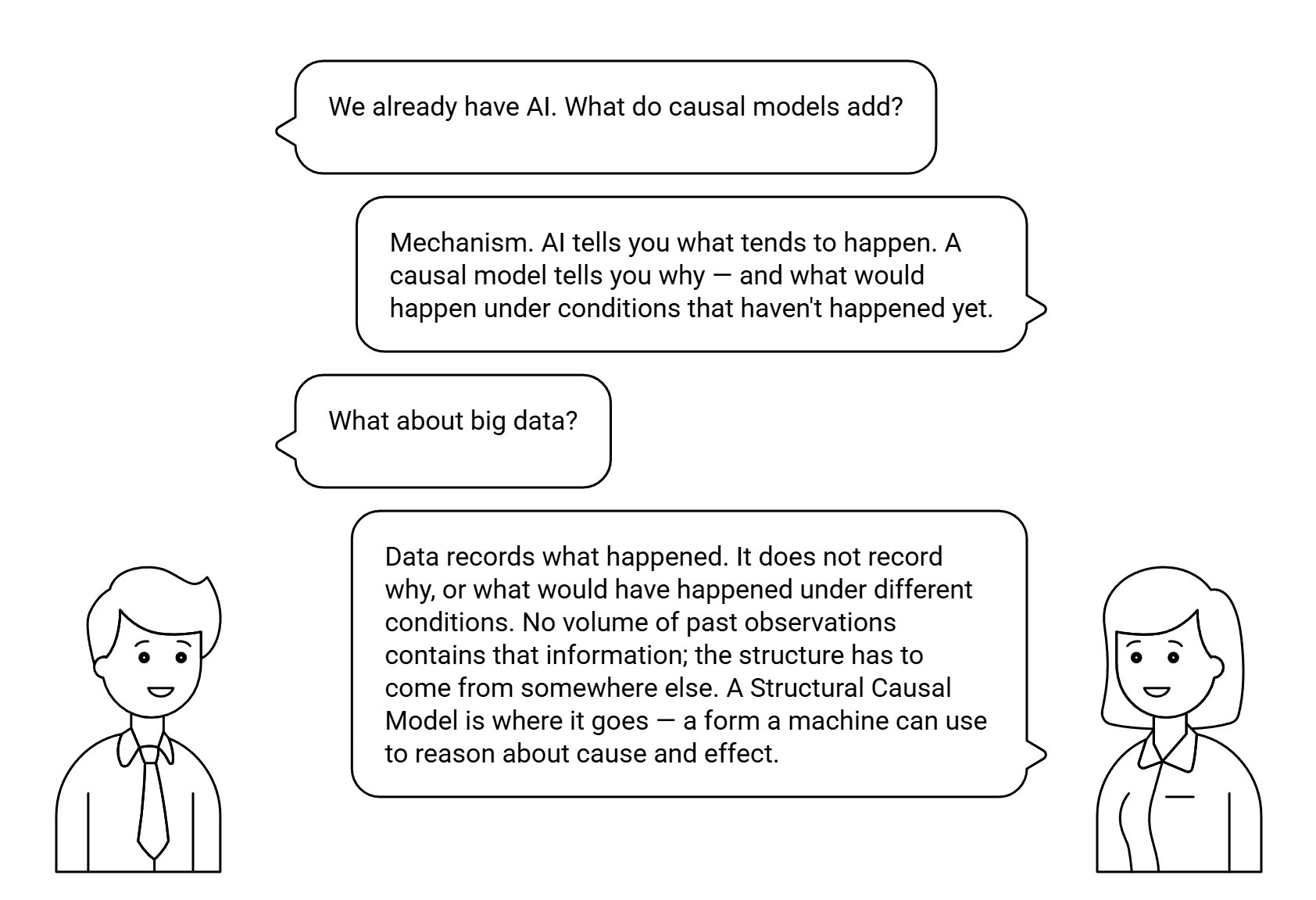
▸But why can’t AI just figure out causation from enough data?
A correlation between two variables is consistent with at least six different causal structures:
- A causes B — the intuitive reading.
- B causes A — same correlation, reverse direction.
- A and B cause each other — feedback, equilibria.
- A common cause drives both — the correlation between A and B is real but neither causes the other.
- Selection — the sample-generating process creates a correlation that doesn’t exist in the population.
- No causal relationship at all — coincidence, or a definitional link (temperature and average molecular kinetic energy are the same quantity, named twice).
The data does not distinguish these. Identifying which structure is true requires bringing something other than the data — temporal precedence, intervention, instrumental variables, mechanistic theory, or a causal graph that encodes domain knowledge.
This is the reason a structural causal model is necessary, not optional. The graph encodes the human judgment that converts a correlation pattern into a causal claim. Full explanation with worked example →
The Engagement

An engagement produces two results.
The first is a team that can reason counterfactually, build the next model, and defend every decision under scrutiny — without me in the room. Your risk analysts. Your actuaries. Your domain experts. Running the next model themselves. Extending it when the problem changes. Explaining it to a regulator or a board without a consultant present. The engagement transfers the capability, not just the output.
The second is a library of precise, accurate causal models — one per domain, permanently owned by your organization. Each model encodes what your domain experts know about why things happen: which variables cause which outcomes, through which mechanisms, with what magnitudes. That structure is what your LLMs currently lack. A language model can describe causation fluently. It cannot compute it. A causal model library gives your AI the reasoning layer it needs to answer the questions that actually matter — what would happen if we acted, what would have happened if we hadn’t.
Education: Golden Gate University San Francisco (MBA) · Stanford (AI) · Johns Hopkins (Data Science)
Resume upon request.
The architecture
A language model is trained on the world’s public writing. It encodes what tends to be true across populations. That is real intelligence, and it is the right tool for questions whose answers do not depend on your particular organization. Most consequential decisions are not those questions. They depend on how your processes interact, which constraints actually bind, and how your experts read evidence the data does not contain. Averages cannot recover the particulars.
The missing layer is a structural account of how your system works — the cause-and-effect graph that your subject-matter experts already carry in their heads, made explicit and queryable. A structural causal model holds that account. The language model and the causal model do different jobs: the LLM brings linguistic fluency and general priors, the SCM brings grounded specificity. Used together, the LLM becomes the interface; the SCM becomes the engine; and the library of models your organization builds over time is the artifact that compounds in value with every engagement.
The work I do is the translation step: helping your experts express their causal knowledge with enough rigour that a machine can reason from it, without requiring them to become machine-learning researchers. A model that captures what your experts know — what drives your outcomes, what constrains your operations, what changes what under which conditions — is not finished when I leave. It is an artifact your team continues to refine as evidence accumulates and the domain changes. The discipline is teachable. The artifact stays with you.
A growing position in the research literature holds that several capabilities considered constitutive of robust general intelligence — persistent world models, counterfactual reasoning, scientific abstraction, transfer learning, explainability, planning under intervention — are not separately available from any current AI architecture, but become natural in an SCM-library architecture.
You do not need that claim to be true to authorize the engagement. But if it is true — and growing portions of the field now think it is — your causal model library, when built, is the kind of artifact this architecture is made of.
Two adjacent arguments: the technical accuracy argument (why SCMs improve LLM accuracy in measurable ways, today) · the research frontier (where the field is heading and what an engagement actually builds today)
The Gap is Logical
Three question types sit on three rungs of a logical hierarchy formalized by Judea Pearl 1: what tends to happen, what happens if we act, what would have happened if we’d acted differently.
These are not variations on the same question. They require categorically different formal structures to answer. The first is a statement about patterns in data. The second requires a causal model that encodes how the system responds to forced change. The third requires a Structural Causal Model that can reason about an individual under a counterfactual condition.
1 Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press. See also Pearl, J., Glymour, M., & Jewell, N.P. (2016). Causal Inference in Statistics: A Primer. Wiley.
What tends to happen?
What happens if we act?
What would have happened if we’d acted differently?
Worked Rung 3 problems across healthcare, insurance, finance, legal, climate. Each opens with the wrong question someone tried to answer with the wrong tool, then walks through the right one.
Concept pages on identification, transportability, mediation, sensitivity analysis, dynamic regimes, and fairness — the mathematics that makes Rung 3 reliable.
Every case study ships with a Bayes Server file you can open, modify, and probe. The numbers on the page were generated by the model in the file.
Clinician · Insurer · Credit risk · Legal · Utilities · ML engineer · Curious
“The tools most organizations rely on were built for Rung 1. The questions boards actually ask require Rung 3.”
No amount of data, no larger model, and no better algorithm can lift a Rung 1 tool to answer a Rung 3 question. The gap is not one of degree. It is one of kind.
A causal model is what closes the logical gap. Not a neural network or a regression — a graph in which nodes are variables and arrows are causal claims. It encodes what your domain experts know about why things happen: which variables drive which outcomes, through which mechanisms, with what magnitudes. Unlike a predictive model, it can be queried for the answers to interventional and counterfactual questions — what would happen if you acted, and what would have happened if you hadn't. That is the structure your board's questions require. It is the only structure that can answer them.
Practical Consequences
Each example case starts with a question a board could not answer because it asked a Rung 3 question with Rung 1 tools. Eight failure modes recur across every domain — each one a logical error, not a data problem.
A board considering a 15% rate increase on a $412M coastal portfolio. The causal model showed the increase would accelerate adverse selection — and identified the cheaper fix the register couldn’t see.
Three suppliers in three countries. The scorecard called it diversification. The causal model found one fabricator with three labels — $23M in concentration risk scored as managed.
The Mission
Every organization that makes decisions under uncertainty deserves the discipline to reason about causation — not just describe correlation. The technology exists. The methodology is mature. What is missing, in most organizations, is the translation: from domain knowledge to causal graph, from causal graph to defensible decision. That translation is a skill, not a product. It can be taught.
The right question answered with the wrong tool produces the wrong answer with high confidence. That is not a data problem. It is a logical problem — and logic has a solution. This practice exists to apply it, and to leave the capability behind.
Recent Work
The methodology has been applied across eleven domains. The depth varies — two are productized, five are case-study portfolios, four are individual cases. A selection:
If you want to build toward a library of causal models your organization can query in plain language — that is the conversation. Thirty minutes. No pitch, no slides. Bring one domain.
info@rung3.ai